
在最近的 IEEE 国际固态电路会议 ( ISSCC ) 上,三星科学家发表了一篇论文,继续推动 DDR5 性能的进步。

三星的目标是通过其新提出的架构将 DRAM 容量提高一倍。
这篇题为 "在第五代 10 纳米 DRAM 工艺中采用对称马赛克架构(Symmetric-Mosaic)的 32-Gb 8.0-Gb/s/pin DDR5 SDRAM "的论文涵盖了目前使用的 16-Gb 架构的局限性和三星提出的对称马赛克布局。在本文中,我们将总结论文中概述的架构的关键组件。
单片裸片(DIE):从 16-Gb 到 32-Gb
目前,最高容量的 DDR5 内存采用基于 16 Gb 裸片并采用 10 纳米工艺制造的三维堆叠 (3DS) 架构。目前主流的终端产品是64GB DDR5 DRAM模块,128GB模块的需求不断增加。
三星论文描述了一款单片 32 Gb 高密度 DDR5 裸片,仍采用 10 纳米工艺。三星声称,基于 32 Gb 裸片的 3DS 系统将提高性能,在八个芯片堆栈中使用时支持高达 1TB 的内存,并实现每个引脚每秒 8 Gb 的速度。
业界认识到需要转向 32 Gb 裸片。然而,存在许多障碍。小于 10 nm 的 DRAM 节点尚未准备就绪,因此芯片制造商必须找到在不改变晶圆厂工艺的情况下增加产能的方法。此外,当前 DRAM 模块的外形尺寸过于固定,无法在不显着提高容量或性能的情况下增加封装尺寸。
“马赛克”架构分区克服传统 DRAM 大小限制
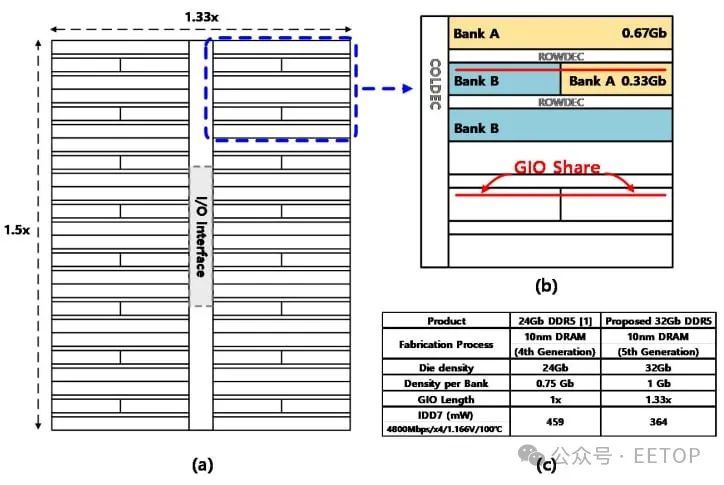
32 Gb 裸片将是一种适应,而不是新标准,因此必须适应传统的 JDEC 规定的 DDR5 外形尺寸限制(最大 10 毫米 x 11 毫米)。在不减小工艺尺寸的情况下增加容量的传统方法包括在存储体中添加 DRAM 单元或将逻辑存储体中的物理存储体数量加倍。这会导致矩形内存占用空间在垂直或水平方向上超过 10 mm x 11 mm 封装尺寸边界框。

传统方法(左)和对称镶嵌方法(右)裸片容量增加的比较。
在所提出的架构中,每个逻辑存储体被分为 ⅓ 和 ⅔ 分区。它们作为逻辑存储体不同分区的对称镶嵌体而间隔开。这使得 DRAM 容量增加了一倍,而水平面积和垂直面积仅增加了 1.5 倍和 1.33 倍(适合边界框)。
来自不同逻辑存储体的两个分区将共享相同的全局 I/O (GIO) 信号线和读出放大器。这种共享减少了 GIO 线路负载电容,从而提高了速度并降低了功耗。这种物理布局将 I/O 保持在中心,与 16-Gb 芯片中使用的一样,共享相同的焊盘结构,并利用类似的硅通孔 (TSV) 结构来连接 3DS 层。
对称马赛克架构
GIO 线的“马赛克”交错和共享利用了保证读到读和写到写时序规范 (tCCD_L) 的精确时序。物理存储体作为逻辑存储体进行划分和访问,tCCD_L 特性用于指示时序。
提高速度并减少干扰
要在如此高的速度下保持数据准确,需要额外的逻辑来实现所谓的决策反馈均衡 (DFE)。高速数字并不是低速情况下简单的“开/关”电压转换。信号是圆形的、受到干扰的,并且通常表现得更像模拟而不是数字。信号线电容和电阻实质上创建了具有 R/C 时间常数的滤波器,该滤波器会扭曲并阻碍携带信息的信号(符号)。一个符号的影响可能会渗透到下一个符号,或者来自接收组件的反射可能会使符号失真,从而导致符号间干扰 (ISI),必须减轻这种干扰以防止无效数据。
三星提出的架构在传统 DFE 电路中添加了四抽头系统,这是传统两抽头 DFE 的替代方案。在 DFE 电路中,抽头被反馈到输入并求和。四抽头直接反馈一抽头以最大限度地减少反馈延迟。第二、第三和第四抽头使用电流模型逻辑 (CML) 求和来进一步提高符号精度。

(a) 四抽头 DFE。(b) 点击一个直接给采样器供料。(c) 将二到四分接至 CML 电路。
DFE 与 DQ 缓冲器中的自动偏移电压校准电路一起运行。校准电路通过使用四个路径进行四个操作阶段来补偿偏移,并根据四个路径输出的直接多数表决进行校准。其结果是能够以 8 Gb/s 或更快的速度可靠运行。
芯片ID预解码
由于每个芯片的 RAM 单元加倍,功耗变得比 16 Gb 芯片更加重要。由于这些芯片将主要安装在 3D 堆叠配置中,因此芯片制造商必须改进针对低效芯片的流程。
“rank”是物理存储体的逻辑组合集,其承载与片上数据总线相同的数据字宽。它可以在物理芯片内形成,也可以在 3D 堆叠芯片系统中跨多个芯片形成。例如,八个堆叠管芯中每一个的左上象限可以组合成一个8位逻辑列并作为一个8位逻辑列进行寻址。
在标准配置中,命令带有芯片 ID (CID) 进入命令总线。然后所有等级都执行解码以查看它们是否是预期目标。解码完成后,仅遵循预期的排名。让所有级别执行解码操作会浪费大量的功率。

(a) 传统的 CID 解码堆栈和 (b) 三星提出的预解码系统。
该提议的架构在每个等级中都带有芯片 ID 预解码。借助此类功能,主列在 TSV 之前具有预解码电路。如果 CID 不是预期目标,它只会将其发送到下一个等级。本质上,堆栈中的每个等级都会在 CID 成为预期目标时停止它。如果堆栈中的最后一个等级是预期目标,则不会节省电量,但对于顶部以下的所有等级,则会节省一定比例的电量。
在当今的外形尺寸内取得进步
三星提出的架构可以在不改变整体外形尺寸或减少芯片蚀刻几何尺寸的情况下大幅提高 DRAM 容量。通过使用更高效的非传统组织结构,可以在不改变标准或工厂的情况下,在相同的面积内容纳更多的容量。建议的架构采用逻辑等级、时序特异性和资源共享来增加容量、降低功耗和提高最高速度。
根据三星的测算,基于 32 GB 的 0.5 TB DIMM 比基于 16 GB 的 DIMM 功耗低 30%,使其成为数据中心和其他容量和功耗要求较高的计算应用的理想选择。
ISSCC 2024 Session Digest PPT(全)
